We’ve updated the DP-300 dumps with 209 Microsoft DP-300 exam actual questions practice material, enough to pass the exam.
Are you looking for DP-300 exam actual questions practice material? Here >> https://www.pass4itsure.com/dp-300.html you can get the latest DP-300 dumps questions.
What do you want to know? DP-300?
The real Administratoring Relational Databases on Microsoft Azure DP-300 exam has 40-60 questions, and you have 120 minutes to complete the exam. The passing score for the Microsoft DP-300 exam is 700. The test languages are English, Chinese (Simplified), Japanese, Korean, French, German, Portuguese (Brazil), Russian, Arabic (Saudi Arabia), Italian, Chinese (Traditional), Spanish, and Indonesian (Indonesia). The exam fee is $165.
Microsoft DP-300 exam learning information:
- Introduction to Azure database administration
- Plan and implement data platform resources
- Implement a secure environment for a database service
- Monitor and optimize operational resources in Azure SQL
- Optimize query performance in Azure SQL
- Automate database tasks for Azure SQL
- Plan and implement high availability and disaster recovery environment
Microsoft Certified: Azure Database Administrator Associate
Successfully passed the DP-300 exam to earn the Azure Database Administrator Associate.
Take one exam > DP-300: Administering Relational Databases on Microsoft Azure > Microsoft Certified: Azure Database Administrator Associate
Why is the DP-300 exam vital to you?
The most straightforward thing is to pass the exam and you can get a good job. Better grasp the future of your IT.
How do I plan to prepare for the Microsoft Administering Relational Databases on the Microsoft Azure exam?
First, you’ll need the Pass4itSure DP-300 dumps, taught in the latest Microsoft DP-300 exam practical question practice material to help you easily prepare for the exam.
Second, you need to practice the DP-300 exam questions diligently.
You can download free DP-300 practice exam questions here:
https://drive.google.com/file/d/1EWEwoOu93IVNlsuxm9cEHfTuaLbnyIvG/view?usp=sharing
Free DP-300 Exam Actual Questions
Q1
HOTSPOT
You are building an Azure Stream Analytics job to retrieve game data. You need to ensure that the job returns the highest scoring record for each five-minute time interval of each game. How should you complete the Stream Analytics query? To answer, select the appropriate options in the answer area.
NOTE: Each correct selection is worth one point.
Hot Area:
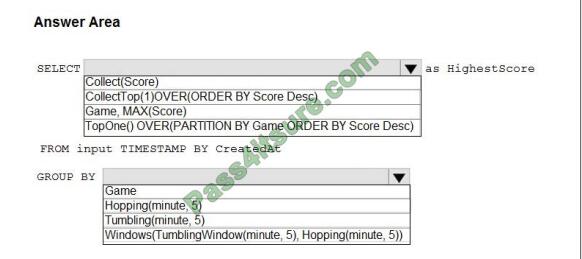
Correct Answer:

Box 1: TopOne() OVER(PARTITION BY Game ORDER BY Score Desc)
TopOne returns the top-rank record, where rank defines the ranking position of the event in the window according to the
specified ordering. Ordering/ranking is based on event columns and can be specified in ORDER BY clause.
Analytic Function Syntax: TopOne() OVER ([] ORDER BY ( [ASC |DESC])+ []
Box 2: Tumbling(minute 5)
Tumbling window functions are used to segment a data stream into distinct time segments and perform a function
against them, such as the example below. The key differentiators of a Tumbling window are that they repeat, do not
overlap,
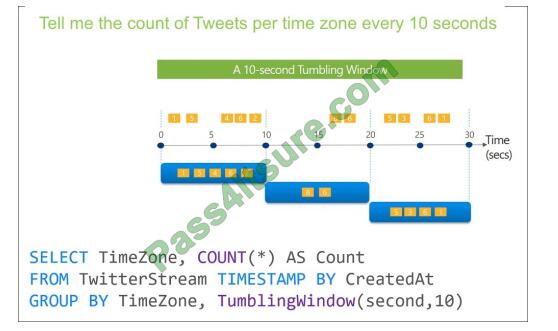
and an event cannot belong to more than one tumbling window.
Reference: https://docs.microsoft.com/en-us/stream-analytics-query/topone-azure-stream-analytics https://github.com/M
icrosoftDocs/azure-docs/blob/master/articles/stream-analytics/stream-analytics-window-functions.md
Q2
A data engineer creates a table to store employee information for a new application. All employee names are in the US
English alphabet. All addresses are locations in the United States. The data engineer uses the following statement to
create the table.

You need to recommend changes to the data types to reduce storage and improve performance. Which two actions
should you recommend? Each correct answer presents part of the solution. NOTE: Each correct selection is worth one
point.
A. Change Salary to the money data type.
B. Change PhoneNumber to the float data type.
C. Change LastHireDate to the datetime2(7) data type.
D. Change PhoneNumber to the bigint data type.
E. Change LastHireDate to the date data type.
Correct Answer: AE
Q3
DRAG DROP
You need to configure user authentication for the SERVER1 databases. The solution must meet the security and
compliance requirements. Which three actions should you perform in sequence? To answer, move the appropriate actions from the list of actions to the answer area and arrange them in the correct order.
Select and Place:
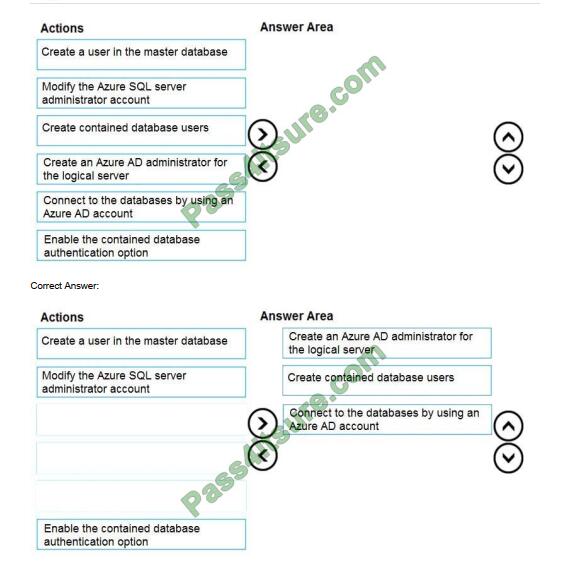
Scenario: Authenticate database users by using Active Directory credentials.
The configuration steps include the following procedures to configure and use Azure Active Directory authentication.
1. Create and populate Azure AD.
2. Optional: Associate or change the active directory that is currently associated with your Azure Subscription.
3. Create an Azure Active Directory administrator. (Step 1)
4. Configure your client computers.
5. Create contained database users in your database mapped to Azure AD identities. (Step 2)
6. Connect to your database by using Azure AD identities. (Step 3)
Reference: https://docs.microsoft.com/en-us/azure/azure-sql/database/authentication-aad-overview
Q4
You deploy a database to an Azure SQL Database managed instance. You need to prevent read queries from blocking queries that are trying to write to the database. Which database option should set?
A. PARAMETERIZATION to FORCED
B. PARAMETERIZATION to SIMPLE
C. Delayed Durability to Forced
D. READ_COMMITTED_SNAPSHOT to ON
Correct Answer: D
In SQL Server, you can also minimize locking contention while protecting transactions from dirty reads of uncommitted
data modifications using either:
1. The READ COMMITTED isolation level with the READ_COMMITTED_SNAPSHOT database option set to ON.
2. The SNAPSHOT isolation level.
If READ_COMMITTED_SNAPSHOT is set to ON (the default on SQL Azure Database), the Database Engine uses row
versioning to present each statement with a transactionally consistent snapshot of the data as it existed at the start of
the statement. Locks are not used to protect the data from updates by other transactions.
Incorrect Answers:
A: When the PARAMETERIZATION database option is set to SIMPLE, the SQL Server query optimizer may choose to
parameterize the queries. This means that any literal values that are contained in a query are substituted with
parameters. This process is referred to as simple parameterization. When SIMPLE parameterization is in effect, you
cannot control which queries are parameterized and which queries are not.
B: You can specify that all queries in a database be parameterized by setting the PARAMETERIZATION database
option to FORCED. This process is referred to as forced parameterization.
C: Delayed transaction durability is accomplished using asynchronous log writes to disk. Transaction log records are
kept in a buffer and written to disk when the buffer fills or a buffer flushing event takes place. Delayed transaction
durability reduces both latency and contention within the system.
Some of the cases in which you could benefit from using delayed transaction durability are:
1. You can tolerate some data loss.
2. You are experiencing a bottleneck on transaction log writes.
3. Your workloads have a high contention rate.
Reference: https://docs.microsoft.com/en-us/sql/t-sql/statements/set-transaction-isolation-level-transact-sql
Q5
HOTSPOT
You have an Azure SQL database that contains a table named Customer. Customer has the columns shown in the
following table.

You plan to implement a dynamic data mask for the Customer_Phone column. The mask must meet the following
requirements:
1. The first six numerals of each customer\’s phone number must be masked.
2. The last four digits of each customer\’s phone number must be visible.
3. Hyphens must be preserved and displayed.
How should you configure the dynamic data mask? To answer, select the appropriate options in the answer area.
Hot Area:

Correct Answer:

Box 1: 0 Custom String : Masking method that exposes the first and last letters and adds a custom padding string in the
middle. prefix,[padding],suffix Box 2: xxx-xxx
Box 3: 5
Reference: https://docs.microsoft.com/en-us/sql/relational-databases/security/dynamic-data-masking
Q6
HOTSPOT
You have a Microsoft SQL Server database named DB1 that contains a table named Table1. The database role membership for a user named User1 is shown in the following exhibit.
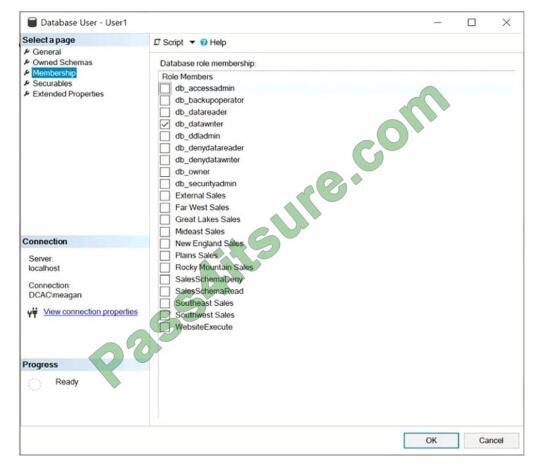
Use the drop-down menus to select the answer choice that completes each statement based on the information
presented in the graphic. NOTE: Each correct selection is worth one point.
Hot Area:

Box 1: delete a row from Table1
Members of the db_datawriter fixed database role can add, delete, or change data in all user tables.
Box 2: db_datareader
Members of the db_datareader fixed database role can read all data from all user tables.
Q7
You are monitoring an Azure Stream Analytics job. You discover that the Backlogged input Events metric is increasing slowly and is consistently non-zero. You need to ensure that the job can handle all the events. What should you do?
A. Remove any named consumer groups from the connection and use $default.
B. Change the compatibility level of the Stream Analytics job.
C. Create an additional output stream for the existing input stream.
D. Increase the number of streaming units (SUs).
Correct Answer: D
Backlogged Input Events: Number of input events that are backlogged. A non-zero value for this metric implies that your
job isn\\’t able to keep up with the number of incoming events. If this value is slowly increasing or consistently non-zero,
you should scale out your job, by increasing the SUs.
Reference: https://docs.microsoft.com/en-us/azure/stream-analytics/stream-analytics-monitoring
Q8
You have the following Transact-SQL query.
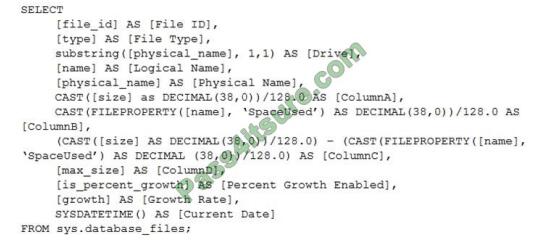
Which column returned by the query represents the free space in each file?
A. ColumnA
B. ColumnB
C. ColumnC
D. ColumnD
Correct Answer: C
Example:
Free space for the file in the below query result set will be returned by the FreeSpaceMB column.
SELECT DB_NAME() AS DbName, name AS FileName, type_desc, size/128.0 AS CurrentSizeMB,
size/128.0 – CAST(FILEPROPERTY(name, \’SpaceUsed\’) AS INT)/128.0 AS FreeSpaceMB FROM
sys.database_files WHERE type IN (0,1);
Reference:
https://www.sqlshack.com/how-to-determine-free-space-and-file-size-for-sql-server-databases/
Q9
You have an Azure SQL database. The database contains a table that uses a columnstore index and is accessed
infrequently. You enable columnstore archival compression. What are two possible results of the configuration? Each correct answer presents a complete solution.
NOTE: Each correct selection is worth one point.
A. Queries that use the index will consume more disk I/O.
B. Queries that use the index will retrieve fewer data pages.
C. The index will consume more disk space.
D. The index will consume more memory.
E. Queries that use the index will consume more CPU resources.
Correct Answer: BE
For rowstore tables and indexes, use the data compression feature to help reduce the size of the database. In addition
to saving space, data compression can help improve performance of I/O intensive workloads because the data is stored in fewer pages and queries need to read fewer pages from disk.
Use columnstore archival compression to further reduce the data size for situations when you can afford extra time and
CPU resources to store and retrieve the data.
Q10
You have an Azure Synapse Analytics Apache Spark pool named Pool1. You plan to load JSON files from an Azure Data Lake Storage Gen2 container into the tables in Pool1. The structure and data types vary by file. You need to load the files into the tables. The solution must maintain the source data types. What should you do?
A. Load the data by using PySpark.
B. Load the data by using the OPENROWSET Transact-SQL command in an Azure Synapse Analytics serverless SQL
pool.
C. Use a Get Metadata activity in Azure Data Factory.
D. Use a Conditional Split transformation in an Azure Synapse data flow.
Correct Answer: B
Serverless SQL pool can automatically synchronize metadata from Apache Spark. A serverless SQL pool database will
be created for each database existing in serverless Apache Spark pools. Serverless SQL pool enables you to query
data in your data lake. It offers a T-SQL query surface area that accommodates semi-structured and unstructured data
queries.
To support a smooth experience for in place querying of data that\\’s located in Azure Storage files, serverless SQL pool
uses the OPENROWSET function with additional capabilities. The easiest way to see to the content of your JSON file is to provide the file URL to the OPENROWSET function, specify csv FORMAT.
Reference:
https://docs.microsoft.com/en-us/azure/synapse-analytics/sql/query-json-files
https://docs.microsoft.com/en-us/azure/synapse-analytics/sql/query-data-storage
Q11
You plan to move two 100-GB databases to Azure. You need to dynamically scale resources consumption based on workloads. The solution must minimize downtime during scaling operations. What should you use?
A. two Azure SQL Databases in an elastic pool
B. two databases hosted in SQL Server on an Azure virtual machine
C. two databases in an Azure SQL Managed instance
D. two single Azure SQL databases
Correct Answer: A
Azure SQL Database elastic pools are a simple, cost-effective solution for managing and scaling multiple databases that
have varying and unpredictable usage demands. The databases in an elastic pool are on a single server and share a
set number of resources at a set price.
Reference: https://docs.microsoft.com/en-us/azure/azure-sql/database/elastic-pool-overview
Q12
DRAG DROP
You have SQL Server 2019 on an Azure virtual machine that contains an SSISDB database. A recent failure causes the master database to be lost. You discover that all Microsoft SQL Server integration Services (SSIS) packages fail to run on the virtual machine.
Which four actions should you perform in sequence to resolve the issue? To answer, move the appropriate actions from
the list of actions to the answer area and arrange them in the correct.
Select and Place:

Correct Answer:
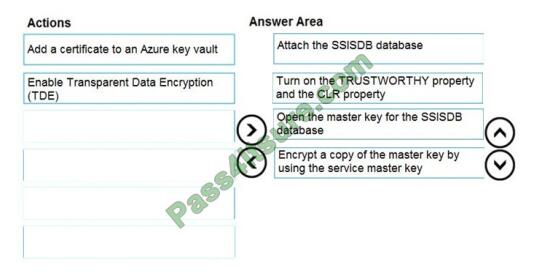
Step 1: Attach the SSISDB database
Step 2: Turn on the TRUSTWORTHY property and the CLR property
If you are restoring the SSISDB database to an SQL Server instance where the SSISDB catalog was never created,
enable common language runtime (clr)
Step 3: Open the master key for the SSISDB database
Restore the master key by this method if you have the original password that was used to create SSISDB.
open master key decryption by password = \\’LS1Setup!\\’ –\\’Password used when creating SSISDB\\’ Alter Master Key
Add encryption by Service Master Key
Step 4: Encrypt a copy of the mater key by using the service master key
Reference: https://docs.microsoft.com/en-us/sql/integration-services/backup-restore-and-move-the-ssis-catalog
Q13
HOTSPOT
You have an on-premises Microsoft SQL Server 2016 server named Server1 that contains a database named DB1.
You need to perform an online migration of DB1 to an Azure SQL Database managed instance by using Azure
Database Migration Service.
How should you configure the backup of DB1? To answer, select the appropriate options in the answer area. NOTE:
Each correct selection is worth one point.

Box 1: Full and log backups only
Make sure to take every backup on a separate backup media (backup files). Azure Database Migration Service doesn\’t
support backups that are appended to a single backup file. Take full backup and log backups to separate backup files.
Box 2: WITH CHECKSUM
Azure Database Migration Service uses the backup and restore method to migrate your on-premises databases to SQL
Managed Instance. Azure Database Migration Service only supports backups created using checksum.
Incorrect Answers:
NOINIT Indicates that the backup set is appended to the specified media set, preserving existing backup sets. If a
media password is defined for the media set, the password must be supplied. NOINIT is the default.
UNLOAD Specifies that the tape is automatically rewound and unloaded when the backup is finished. UNLOAD is the default
when a session begins.
Reference:
https://docs.microsoft.com/en-us/azure/dms/known-issues-azure-sql-db-managed-instance-onlin
There are 209 questions in the full exam, this is just 13 of them, keep reading for other questions, download the DP-300 dumps https://www.pass4itsure.com/dp-300.html
